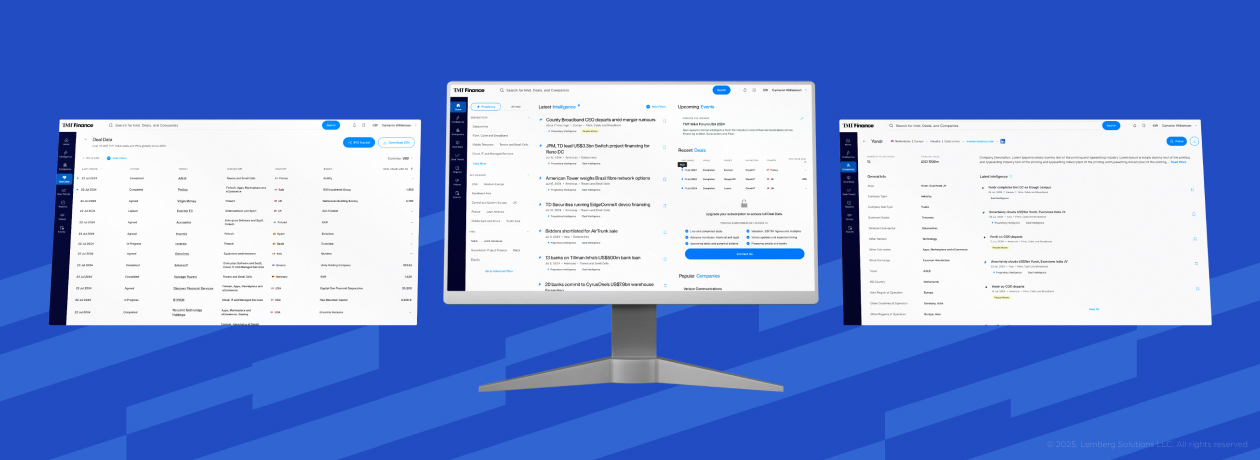
Sector(s)
Visit the site
Visit the siteAs the database of a leading financial data platform provider continued to grow, its system became increasingly difficult to navigate and manage. Discovery was slow across large datasets. Granular data interrogation was cumbersome or impossible across certain data points. The permissions model couldn't support the subscription tiers the business wanted to sell, and content management didn't scale with volume.
Lemberg Solutions transformed the Drupal-based environment into a scalable financial intelligence platform with advanced search, analytics, notifications, and content management capabilities. The new architecture supports granular, region-based access control and flexible subscription models. Together, these significantly improved the experience for both administrators and end users. Since the relaunch, the platform has been delivering 43% faster data retrieval speeds than before.
About the project
Over the years, the leading data platform for digital infrastructure investment grew rapidly. Its original system, holding over 20,000 company records, 15,000 intelligence articles, and 10,000 deals, was outpaced by the volume it had to handle, exposing issues with how the platform had been designed and built.
To enhance its Drupal platform, the business turned to Lemberg Solutions. The business chose to modernise on Drupal rather than replatform, and the rebuild proves Drupal can scale to meet enterprise-grade demands. The project included a full platform redesign, restructuring of the databases and content management system, and migration of existing content to the enhanced solution.
The work was phased. With the core restructuring complete, the team layered on the capabilities that now define the platform: granular access control, real-time analytics, multi-channel notifications, and flexible data export. Access is governed by a granular role-based model with a custom permissions layer, enabling region- and tier-based subscriptions.
The platform delivers real-time analytics on financial datasets: users can benchmark market performance and explore insights through advanced search and filtering. A notification system provides personalised intelligence via email and a custom Microsoft Teams app, while a data export framework supports offline analysis across multiple formats.
The result is a platform that turned slow, hard-to-navigate datasets into fast, precise discovery across more than 20,000 company records, 15,000 intelligence articles and 10,000 deals, with proactive alerts delivered by email. A custom permissions layer unlocked the region- and tier-based subscriptions the business had been unable to offer before.

Goals & results
The goal of the project was to make a growing data platform easy to operate at scale. On the business side, this meant maintaining a high volume of content without losing control over quality. For users, it meant reducing the time and effort needed to navigate large datasets and find insights.
Alongside significantly enhanced usability and navigation, the modernisation delivered:
- Faster, more precise data access: around 200 custom plugins make deep discovery effortless, cutting query/search latency from 3.0-3.5s to 1.7-1.8s.
- Granular access control with region- and feature-based permissions, letting clients buy access by region or content tier and unlocking multiple subscription tiers the previous system could not support
- A future-proofed architecture supporting decoupled frontends and external integrations, opening the platform's evolution into a Data-as-a-Service (DaaS) offering.
- Real-time notifications across email and a custom Microsoft Teams app, delivering 80K-90K alerts per month, so users never miss critical market intelligence.
- Offline working through exports in Excel, PDF, and CSV and PowerPoint, handling exports of up to 7K-10K rows, so data flows easily into customers' internal systems.
- Improved content referencing that connects related deals and companies for richer context.
- Streamlined content management: a more structured, intuitive system for maintaining data at volume.
Challenges
Each of these challenges came down to the same question: could Drupal handle enterprise-scale financial data without buckling? Solving them meant building well beyond Drupal's defaults.
A key one was processing and aggregating large volumes of financial data in real time to power company insights. To address this, we used a custom Search API backend to offload heavy statistical calculations directly to Solr. Custom-built field plugins enabled calculation and display of financial metrics instantly, while handling missing or inconsistent data.
We also had to build a notification system capable of delivering personalised alerts across multiple channels, including email and MS Teams. For better reliability and scalability, developers implemented a decoupled, queue-based architecture, which ensures alert generation doesn't affect platform performance, processing up to 5K-6K alerts per day without measurable impact.
The export feature needed to handle large amounts of data in different formats including Excel, CSV, PDF and PowerPoint. Our engineers used a two-pass streaming architecture with dynamic field generation to process complex relational datasets without memory issues, handling exports of up to 15MB of data in approximately 20-30 minutes.
Another key challenge was building a flexible permissions system for feature, content, and region-based subscriptions. By combining standard Drupal roles with a custom access management system, we ensured consistent permission control across more than 20 region and tier combinations. To maintain performance, regional restrictions are cached at multiple levels.
Finally, the search and filtering experience required deep customisation to support fast discovery across complex financial records. This was addressed through Solr-based indexing, flattened data structures, and custom filters for precise numeric and date range querying, returning results across the full dataset in under 1.7-1.8s.
Why Drupal was chosen
Many innovations struggle to reach the community because generalising specialised functionality into reusable modules requires significant effort. After solving performance and structural issues for a large financial data platform, we are working on turning this custom implementation into a community contribution for the next generation of large-scale Drupal applications.
The upcoming contributions aim to enrich the Search API, Search API Solr, and Facets ecosystems. This includes generalising our custom facet plugins to allow Drupal setups to leverage Solr's native backend facets API, unlocking significant retrieval speed improvements — 43% faster — for the wider community. A generalised version of our flattening processors will provide a framework for mapping and indexing deeply nested relational data without performance degradation.
Our work with tens of thousands of financial records also enabled us to identify minor stability bottlenecks under high loads. We are documenting these findings and preparing to submit them as stability patches directly to the issue queues.
Technical Specifications
Drupal version:
Key modules/theme/distribution used: